Intrigue Core is the open attack surface enumeration engine, and the open core that powers Intrigue.io.
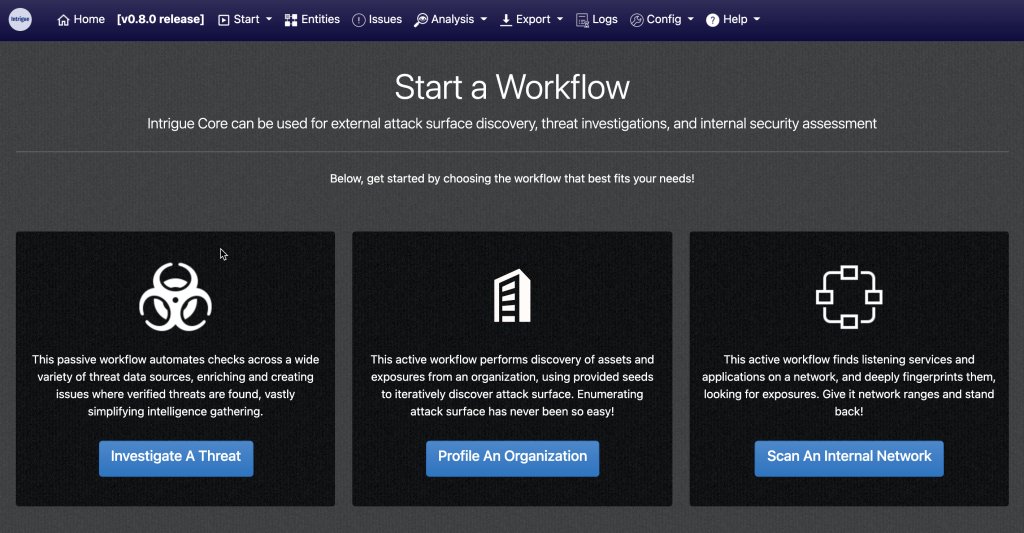
Intrigue Core integrates and orchestrates a wide variety of security data sources, distilling them into a normalized object model and tracing relationships via a graph database.
Intrigue Core is open source software. It’s maintained and copyrighted by Intrigue Corp, made available on the Intrigue Team Github. Information about the latest release can be found in the Gettting Started section..
Our community can be found on the Intrigue Community Slack, feel free to jump in and ask questions!
